Robot Game: 65C02 Language Comparison
A few years ago, I started doing small projects with the 65C02 processor to build up to using it to make a graphing calculator. There are a few different languages that you can use to write programs for this processor with assembly offering the best performance. One of the projects I worked on is an optimizer to make assembly programs run faster. It works by tracing program flow then assigning fixed addresses to local variables in functions instead of storing them on the stack. To figure out how much of an improvement the optimizer adds, I made a game in Python then ported it to both traditional assembly and the new optimized assembly format. I also ported the game to C and Forth to see how fast they are compared to the assembly versions.
Play the game in your browser:
Robot Game - Traditional assembly version
Robot Game - Optimized assembly version
Robot Game - C version
Robot Game - Forth version
GitHub links:
Robot Game - All versions
65C02 Emulator
65C02 Assembly Optimizer
Table of Contents
- Why 65C02?
- The Languages
- The Simulator
- The Game
- Extracting Game Assets
- Porting the Game to Traditional Assembly
- Porting the Game to Optimized Assembly
- Porting the Game to C
- Porting the Game to Forth
- Speed Comparison
- Size and Time to Implement
- Code Analysis: rand
- Code Analysis: CalcStats
- Conclusions
- Areas for Improvement
Why 65C02?
The 65C02 is an improved version of the 6502 used in the Atari 2600, Nintendo Entertainment System (NES), and the first two computers made by Apple. Because the 65C02 is made with more modern CMOS transistors, it’s much more energy efficient and runs at up to 14 MHz, compared to the 1-3 MHz of the original 6502. Both of these things make it a good choice for a graphing calculator. For comparison, the very common TI-83+ made by Texas Instruments has a Zilog Z80 running at 6 MHz. Since the Z80 needs 3-4 times more cycles to accomplish the same work as a 6502, a 65C02 running at full speed should be 7-9 times more powerful than the Z80 in a TI-83+. Another advantage of the 65C02 is that it’s still sold in a DIP package, so it’s easy to find and experiment with on a breadboard. There aren’t many better choices in a throughhole package. The Motorola 68000 is more powerful MHz for MHz, but it's already used in the TI-89, so I would like to use something different. Some throughhole microcontrollers have much more processing power, though not much RAM and no way to add more without an external address bus. The throughhole PIC32, for example, runs at up to 50 MHz, but only has 64 KB of RAM. For comparison, the TI-89 introduced in 1998 and the HP-49G from 1999 had 256 KB and 512 KB of RAM respectively. Since the 65C02 has an open address bus, there is no limit to the amount of RAM and ROM it can access.
The Languages
These are the languages that I want to compare:
- Traditional assembly - This is plain old 65C02 assembly. Like many 65(C)02 (ie 6502 or 65C02) programs, it uses the X register as a stack pointer for a data stack (more details on this below). Some functions copy and save data from the fastest region of memory called zero page to free it up for use and restore the data when the function ends (more details on this below too).
- Optimized assembly - This version of the game differs from traditional assembly since it doesn’t use the X register as a data stack pointer. Instead, local variables in each function are assigned a fixed address at compile time. The addresses are determined by a Python script that analyzes the flow of the program and tracks how much memory each function needs (more details below).
- C - This version is compiled with CC65, which seems to be the most popular C compiler for the 65(C)02.
- Forth - This version is compiled using a modified version of Tali Forth 2. I picked this Forth since it generates subroutine threaded code (STC) which is generally the fastest, though largest, type of Forth code.
The Simulator
65C02 Emulator on GitHubAll of the code runs on a JavaScript-based simulator I made that works in the browser. The simulation itself runs very fast on a separate thread using a web worker, while the main page is only responsible for the interface. This setup lets the simulation run at the equivalent of 40-50 MHz, several times faster than an actual 65C02 running at 14 MHz. Because it runs in the browser, you can try each version of the game for yourself:
Robot Game - Traditional assembly version
Robot Game - Optimized assembly version
Robot Game - C version
Robot Game - Forth version
The simulator has sixteen memory banks of 16 KB each for a total of 256 KB of memory. The 65C02 has a 16 bit address bus, so it can only address 64 KB of memory at a time. To access the memory outside of the first 64 KB, the simulator simulates a memory banking system. Each 16 KB range of the 64 KB address space can point to any of the sixteen memory banks. This was a common strategy in retro computers to get around the limitations of a small address space.
Memory map:
- 0x0000 to 0x01FF - No banking
- 0x0200 to 0x3FFF - Memory window 1
- 0x4000 to 0x7FFF - Memory window 2
- 0x8000 to 0xBFFF - Memory window 3
- 0xC000 to 0xFFDF - Memory window 4
- 0xFFE0 to 0xFFFF - Peripherals
The first 512 bytes are not banked since they contain the fast zero page memory and the hardware stack which always need to be visible from all banks. The last 32 bytes are for peripherals like the keyboard and for vectors for reset and interrupts. Each peripheral is assigned a specific address in this range, and the processor communicates with them by reading and writing to those addresses. Four bytes in the peripheral region control which of the sixteen memory banks each window points to. For example, if memory window 2 points to memory bank 7, then reading the first byte of memory window 2 at 0x4000 will access the first byte of memory bank 7 which is at 0x1C000.
The video memory is mapped one byte per pixel and takes up the 32 KB from 0x10000 to 0x17FFF (memory banks 5 and 6). The resolution is 256x128. Each byte has two bits each of red, green, and blue. Valid color codes are therefore 0-63.
The simulator has some interesting tools that helped port the game. Some of them were added during development because a specific problem arose that I needed to add them for. The main page lets you step through the code and shows the status of all the registers and each memory region that it accesses. There is also a memory viewer and a log of exactly which instructions have been executed. Copying this information into Excel or a text diff program helped track down several bugs in the game.
 Simulator debug interface
Simulator debug interface
Getting the cycle counts right for the executed instructions was a little tricky. For example, when an X-indexed instruction fetches an address where adding X to the low byte of the address overflows and the high byte of the address has to be adjusted, the instruction takes an additional cycle. After I got the logic for that fixed, the test code I was using was still a few cycles out of 3.5 million cycles off. Single stepping the program through all of those cycles to figure out which instruction was off would take too long. Instead, I loaded the code into the Kowalski simulator then used a Python script to automate pressing the single step button and record the cycle count for every instruction. This generated way too much data to load into a spreadsheet, so I made another script to compare those cycles to the ones I generated in my own simulator and tracked the problem down to incorrect cycle times for the STZ instruction.
The Game
Robot Game on GitHubThe game is made in Python with the PyGame library. It was easy to read one big image into memory then copy parts of it into individual tiles that PyGame draws to the screen. Here are the images I came up with in Paint:
 Graphics tiles for Robot Game
Graphics tiles for Robot Game
Several of these are tiles that I was experimenting with that didn’t make it into the game. Bright magenta (0xFF00FF) and bright cyan (0x00FFFF) are replaced with transparency when the tiles are created. Most of the tiles only have placeholder colors and are used as the basis to create other tiles. For example, the green, yellow, and grey color in the generic crystal graphic above are filled in depending on what type of crystal the game needs to draw:

The rock and lava tiles are constructed similarly from the generic tile above. There are four dirt tiles that are colored slightly differently and rotated at 90, 180, and 270 degrees to give the background some variety:

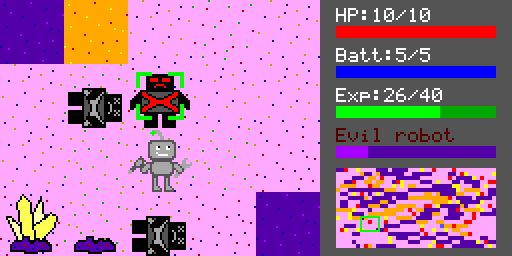
There is only one type of monster which is always colored the same, so a few tiles like that don’t have any pixels that change colors. Adding in some stats and a randomly generated map gets us to the main game window:

The map is formed from the output of a random number generator. Using the same generator algorithm for each port results in the same beginning map for all four versions (and the same gameplay if the player makes the same decisions). I had to try several seed values for the RNG until I got a map I liked the look of as seen in the screenshot above. Here are a few that didn’t make the cut:

The rest of the game is just the three menu screens. The first displays a couple of stats and an inventory page. Moving the cursor over an item shows that item’s stats and what is currently equipped in that slot. Equipping an item changes the color of the corresponding part of the robot to match. In the tiles page above, the image of the robot is drawn with different colors that all correspond to the same colors that the generic item tile has. This means that the easy find and replace function to color in the individual items also works with the same color information on the larger image of the full robot.
 Robot Game character menu
Robot Game character menu
The skills page is pretty straightforward. There are three paths and unlocking any skill requires first unlocking the skill before it in that path. Every time the player levels up, they get one skill point.
Skills:
- Battery Saver - 20% chance that mining won't consume energy
- Bounty Hunter - 10% chance of crystal when you kill an enemy
- Fast Digger - -2 Mine and Drill time
- Lucky Driller - 25% chance of crystal when mining rock
- Master Miner - Mine double crystals
- Lucky Crit - +20% chance of critical hit
- Crit Lord - Crit damage raised from 150% to 200%
- Experienced - +10% bonus to experience on kill
- Instakill - 5% chance to kill enemy in one hit
- Ghost - Walk through enemies
- Free Lunch - 20% chance that crafting will cost nothing
- Wise Rewards - +5 random crystal when leveling up
- Big Discount - -1 to cost of items
- Only the Best - 10% chance that crafted items will be yellow quality
- Crystalsmith - Pay with any crystal
 Robot Game skills menu
Robot Game skills menu
The last menu screen is the resources page where the player can use the minerals they find to buy new gear and upgrade their character.
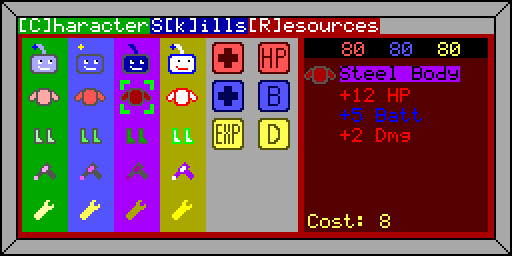 Robot Game resources menu
Robot Game resources menu
The gameplay involves walking around the map looking for minerals and optionally fighting the enemy robots. Each time the user presses a direction key, the character moves exactly one map tile, so there is no walking animation between tiles. The lava tiles cause damage, which upgraded boots can reduce or eliminate. The rock tiles block the player but can be drilled through. Drilling, mining a mineral, or attacking a monster are all controlled by a timer that ticks once per second. Information about the currently highlighted rock/mineral/enemy is displayed on the right above the mini map. The enemies don’t move, and they don’t attack the player until they are attacked themselves, but they grant a lot of experience when killed.
Extracting Game Assets
Asset extractor on GitHubCramming all the game graphics into one large graphics file works fine on a PC but not so well on the simulated 65C02 where there is a lot less memory. The graphics tiles need to be converted into a format that can be embedded into source code. Once the Python version of the game was working, it was easy to access the individual pixels of the tiles in memory then output the pixel data to text. To save on memory, the pixel data is compressed with run length encoding (RLE), so instead of one byte per pixel, tile data comes in pairs with the first number representing the number of pixels and second representing the color. Here’s an example:

Uncompressed:
RED,
RED,
RED,
BLUE,
BLUE,
BLUE,
BLUE,
BLUE
Compressed:
3,
RED,
5,
BLUE
With larger images, this type of compression saves a lot of space. The simulator assigns colors to pixels numbered 0-63, and 64-255 are unassigned. The encoding to text assigns 64 to transparent then assigns each recolorable pixel color to a number larger than 64. This speeds up coloring in the tiles since the 65C02 routine can ignore any pixels it finds that are under 65 since they won’t be recolored. This system lets every set of recolorable pixels in the tileset have a unique value so the program doesn’t have to keep track of what a particular color represents in a particular tile. For example, both of these tiles have yellow, but the yellow pixels in each tile are assigned unique IDs above 64 in each case so the program doesn’t have to keep track of what yellow represents for each tile:

Other images only contain two colors and can be compressed even further using only one bit per pixel (1 bpp), as in the skill tiles below. One tricky thing that I didn't realize until I started porting everything was that I hadn’t encoded the rounded transparent corners which would technically be a third color - transparent. Instead, I added a one byte flag to each 1 bpp tile and did the corner transparency in code.
Another thing that streamlined porting was calculating the offsets of all of the graphical elements like labels and progress bars. These don't change from port to port and can be assigned the same constant name. From there, it's easy to put the 250 or so constants in a spreadsheet and quickly format them however the target language expects.
Porting the Game to Traditional Assembly
Robot Game - Traditional assembly on GitHubThe 65(C)02 is an 8-bit architecture and has three main 8-bit registers. The A register, or accumulator, is used for most calculations and moving data. The X and Y registers, on the other hand, are used for indexing into memory or counting up or down by one. They can’t be used for general purpose calculations like A. One use for the X and Y registers is stepping through memory. For example, you can access the elements of an array by loading the index into X then using this instruction:
This copies the byte of the array that is X bytes past the beginning into the A register. To step through the whole array, just keep increasing X by one and loading the data into the A register (remember, X can’t do arbitrary calculations, only increasing and decreasing by one).
The first 256 bytes of memory on the 65(C)02 are special. This area is called the zero page. Because addresses for zero page can fit into 8 bits instead of the 16 for all other addresses, the processor can load the address and access this memory one cycle faster. Since instructions only take 2-7 cycles, shortening an instruction by one cycle leads to a meaningful speed up. As a result, the scarce but faster zero page memory is always at a premium.
Many programmers use the X register as a dedicated data stack pointer and keep that stack in zero page since stack memory is used for local variables in functions and should be as fast as possible. In this case, you can think of the address supplied to the instruction as the offset into the stack. This instruction for example would load the second item on the data stack (offset 0 would be the first):
The 65(C)02 also has a dedicated stack pointer called SP for the hardware stack, but unlike many architectures, there is no addressing mode that allows access at an offset into this stack. This type of addressing, for example, is not valid:
For this reason, the X register is usually used as a data stack pointer and the hardware stack SP is mostly used for return addresses. In order to use the X register for a data stack, every function should decrease X to make some temporary room for local variables then restore X when the function is finished with the local variables and returns. Here is an example:
foo: DEX ;decrease X making room for two bytes on stack DEX LDA #5 ;load the number 5 into the A register STA 0,X ;store 5 into first byte on stack INC ;increase value in the A register from 5 to 6 STA 1,X ;store 6 into second byte on stack INX ;release the two bytes reserved on stack INX RTS ;return from function
This makes room on the data stack for two bytes, stores a 5 in the first byte, and a 6 in the second byte. At the end, it restores X and returns from the function. This method is flexible since functions can use as many local variables as needed as long as there is still stack space, and it supports recursion.
One small improvement (highlighted) is adding a PHX to save the value of X on the hardware stack. This lets us replace the two INX instructions at the end of the function with PLX to pull X off the hardware stack and restore it to what it was before the function started. With this setup, DEX can be used to reserve as many bytes as necessary in a function without having to balance it with an equivalent number of INX instructions at the end:
foo: PHX ;save current data stack pointer to hardware stack DEX ;decrease X making room for two bytes on stack DEX LDA #5 ;load the number 5 into the A register STA 0,X ;store 5 into first byte on stack INC ;increase value in the A register from 5 to 6 STA 1,X ;store 6 into second byte on stack PLX ;restore data stack pointer from hardware stack RTS ;return from function
Once the system for allocating local variables is in place, the code can be shortened with macros. Different assemblers can have very different macro capabilities. Macroassembler AS is a powerful one and worked pretty well for this project. Storing the state of functions and other structures in string variables at assembly time allows you to create some extremely powerful macros as I show below. We can generate the code above with macros that are a little easier to read:
FUNC foo ;declare function foo
VARS
BYTE bar, baz ;make room on stack for two byte-length locals
END
LDA #5 ;load the number 5 into the A register
STA bar,X ;store 5 into local variable bar
INC ;increase the value in A register from 5 to 6
STA baz,X ;store 6 into local variable baz
END ;restore stack pointer and return
This has several advantages. There's no need to count how many DEX instructions are needed since the VARS and END macros handle that. Also, it allows the use of named variables, which makes the function much easier to read. The next step is to add support for 16-bit variables where we can use the keyword WORD in addition to BYTE. Here’s another example:
FUNC fruits ;declare function fruits
VARS
BYTE grape ;declare one byte-length local variable
WORD banana, pear ;declare two word-length local variables
END
LDA pear,X ;copy first byte of pear to first byte of banana
STA banana,X
LDA pear+1,X ;copy second byte of pear to second byte of banana
STA banana+1,X
END ;restore stack pointer and return
This code copies the 16-bit value pear to the 16-bit value banana. This is a little tedious because it takes four steps to do what would be something like “banana=pear” in most other languages. Those four lines can be shortened to one line with a macro:
MOV pear,banana ;note source, destination order
This will make life a lot easier with 16-bit values. What happens when 8-bit and 16-bit values are mixed like this?:
MOV grape,banana ;grape is 8-bit though banana is 16-bit!
This will copy the low byte of grape to the low byte of banana, which is correct, but then copy the byte after grape to the high byte of banana, which is wrong since grape doesn’t have a high byte. We can get around this by having the BYTE macro record that grape is a byte and having the WORD macro record that banana is a word when they are declared so that MOV can intelligently choose not to copy the high byte of a variable that doesn’t have one. On the other hand, when copying a BYTE to a WORD, the macro will copy a zero into the high byte of the destination. This allows MOV to work correctly with any combination of BYTEs and WORDs.
What happens when only the low byte of a WORD needs to be copied into another WORD? For that, there is a separate MOV.B macro that only copies a byte even if the type is WORD and also a MOV.W macro that copies a whole word regardless of the destination type.
The next improvement is adding two more type keywords: ZPBYTE and ZPWORD. These will be used to assign variables to the fast zero page memory but not by using the X register to keep track of them on a stack. Instead, they will be stored at a fixed location in zero page, and whatever data is at that location when the function starts will be copied to the hardware stack then restored when the function ends. In other words, these variables will have several cycles of overhead at the beginning and end of the function they are used in, but they will be one cycle faster to access since they don’t have the overhead of being relative to the X register when they are accessed. So how do you know when to use each type of variable? The overhead for creating a ZPBYTE variable is about 20 cycles and for ZPWORD around 33. As long as a variable is accessed enough times to justify the 20 or 33 cycle overhead cost at creation, variables declared with ZPBYTE and ZPWORD will be faster than ones declared with BYTE and WORD. As I realized below, I chose the wrong type at least once.
The next piece of the puzzle is passing arguments to functions. For this there is an ARGS macro that works similar to the VARS macro:
FUNC test ;declare function test
ARGS
BYTE foo, bar ;function takes two byte-length arguments
VARS
ZPBYTE baz ;declare one byte-length local variable in zero page
END
...
END ;restore stack pointer and return
This allocates two bytes of input to the function. Values are passed with a CALL macro:
CALL test, #5, value ;call function test passing arguments #5 and value
This copies #5 to foo and value to bar then jumps to label test. The convenient thing about this is that because CALL relies on MOV.B and MOV.W internally, it properly copies the data into the incoming arguments for the function regardless of type. It also knows to add “,X” to the end of variable names declared with BYTE and WORD and to leave it off for variables declared with ZPBYTE and ZPWORD when copying. Functions can return a value in a dedicated global variable set aside for the purpose called ret_val. Callers can copy the value from there to their own memory if needed.
The last data type is STRING and normally functions like a WORD since the address of a string is a 16-bit number. The one difference is that a literal string can be passed to the CALL macro in which case the string will be embedded in the program and it’s address filled into the STRING variable. These two examples are equivalent:
string_address: DB "Hello, World!",0 ;literal string data ... CALL DrawText,string_address ;call DrawText passing string_address CALL DrawText,"Hello, World!" ;call DrawText passing string directly
The last piece of the macro puzzle is to add structural keywords like IF and SWITCH. Unfortunately, those are already taken by the assembler so I went with IF_EQ and WHICH instead. I added several aliases for the IF statements like IF_0 and IF_FALSE for IF_EQ to make the source more readable. The macros keep track of the nesting of all structures so they can be nested and mixed freely. Here’s an example:
FUNC test
ARGS
BYTE value, secondary
VARS
WORD result
END
...
WHICH value ;switch (value)
LIKE #0 ;case where value==0
MOV #1234,result ;copy 16-bit immediate to variable result
LIKE #1,#2,#3 ;case where value==1, 2 or 3
MOV #5678,result ;copy 16-bit immediate to variable result
LIKE #4 ;case where value==4
LDA secondary,X
IF_0 ;if variable secondary==0
MOV #ABC,result
ELSE_IF ;if variable secondary!=0
MOV #DEF,result
END_IF
DEFAULT ;default case where above cases don't match
MOV #0,result
END
...
END
This looks much cleaner than it would in pure assembly. Getting these macros working was a huge step towards porting the game and made working with assembly much more enjoyable. There are a handful of other macros that make things easier like INC.W and ROR.W as well.
There were a few speed bumps creating this version of the game. Implementing the random number generator had me stumped for a while. This is the algorithm I found on a retro programming website:
rand_val^=rand_val<<7; rand_val^=rand_val>>9; rand_val^=rand_val<<8;
The output of the generator in assembly was correct for many cycles then diverged from the C version at some point. This caused the randomly generated map to look close but not identical to the other versions. (Testing the output in Python, I realized the interesting property that this algorithm generates every 16-bit value exactly once before repeating.) This algorithm is convenient on an 8-bit architecture since shifting a 16-bit value left 7 is the same as shifting the low byte right just once and moving it to the high byte. Shifting 9 right on the next line is also very efficient since it's equivalent to switching the high byte to the low byte then shifting right once. The 65(C)02 can only shift one bit at a time, so reducing these arguments to one-bit shifts makes them much more efficient. The problem I ran into was that shifting right once to accomplish the shift left by 7 needs to shift in a bit to fill the most significant bit of the 16-bit value during the single shift right. Because I missed this, the random values happened to be right for a while before diverging.
This is an important lesson. Assembly takes longer to write than other languages, especially when you consider the mistakes you wouldn’t make in other languages. The algorithm is too simple to mess up in C, but I spent a good amount of time stuck on this before I realized my mistake in assembly.
Another challenge was how long it takes to assemble. As shown above, a lot of the code relies heavily on macros. Macroassembler AS copies the entire body of the macro into the source each time it’s called which includes all of the code paths that weren’t taken. For example, the MOV.W macro is over 200 lines long, so the assembly listing that the assembler generates grows by that length for every occurence of MOV.W in the source. This causes the listing to balloon to over 26 MB every time it’s assembled which can take up to 10 seconds. A Python script filters all of the extra lines out of the listing so that it appears correct when loaded into the simulator. The long assembly time will be impractical when the program size grows 10 times larger or more for the calculator I want to build.
The last hiccup was trying to create the equivalent of an array of structs in assembly. This is how I stored the information related to the monsters and crystals placed throughout the map. In C, the compiler would figure out the size of the struct and multiply the array index by this value to access the correct member of the struct. In assembly, I hard coded a series of shifts and adds to accomplish the multiplication based on the size of the struct since it’s constant. Unfortunately, I miscalculated the size and wasted a lot of time trying to figure out why the data was wrong. This type of mistake doesn’t happen in C since the compiler does the calculation for you.
Porting the Game to Optimized Assembly
Robot Game - Optimized assembly on GitHub65C02 Assembly Optimizer on GitHub
This version is based on the traditional assembly version above, so porting it did not require much work. The main task was rewriting all of the above macros to work with my assembly optimizer program. For this, I switched from using Macroassembler AS to NASM which is actually an x86 assembler. NASM allows you to define and expand macros in a file without checking whether the file consists of valid instructions, so running it on 65C02 assembly is no problem. It also has a better system for dynamically defining symbols and labels which let me pass useful information from the macros to the optimizing program. This is the compiling process:
- Run NASM on 65C02 source. Macros are expanded which support structures like IF and WHICH. Local variables are identified but not assigned an address. Output processed assembly instructions to a file.
- Pass the processed assembly file from NASM to the assembly optimizer Python script. The optimizer assigns optimal zero page addresses for local variables and outputs the processed assembly to a file.
- Pass the processed assembly file from the optimizer to Macroassembler AS which outputs a binary file.
The optimizer starts by tracing which functions each function calls starting with the very first function. It also records how many bytes for local memory each function needs which the macros expanded by NASM have identified. From this information, it constructs a call graph:
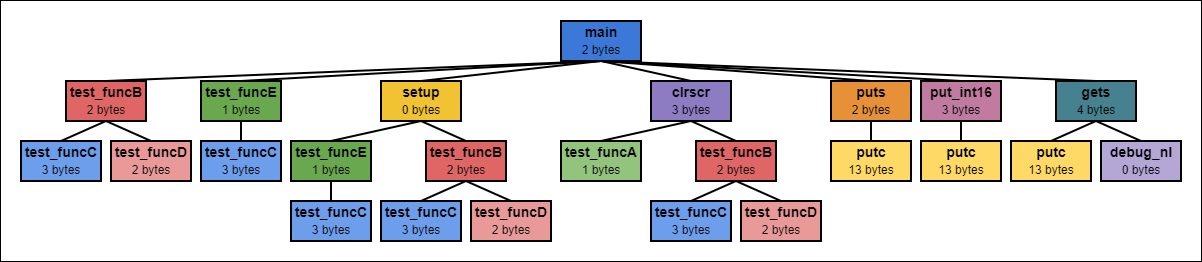
Call graph generated by 65C02 Assembly Optimizer
The optimizer assigns memory addresses to local memory by using the call graph information to find addresses in the fast zero page memory for each variable that aren’t reused by any of the functions that that function calls. For example, in the graph above, the functions main and clrscr must be assigned different addresses for their local variables. If not, the data that main stores at its assigned addresses would be overwritten by the local variables clrscr uses. On the other hand, the functions clrscr and putc can be assigned the same memory addresses. It’s clear from the graph above that putc and clrscr never call each other or call functions that call either of them, so it's safe for them to reuse the same memory. Here is a table of memory assignments that the optimizer outputs:

Static memory allocation generated by 65C02 Assembly Optimizer
Each row represents one byte of fast zero page memory and each box represents a variable that uses that byte of memory. As the table shows, byte 2 is used by six different functions in this small example. As mentioned aboved, the memory for putc and clrscr overlap, and main uses a different part of memory than clrscr.
Assigning fixed zero page addresses to local variables at compile time means that they no longer have to be indexed to the X register. This has several advantages:
- Accessing a fixed address in zero page is one cycle faster. For example, LDA address where address is in zero page is 3 cycles while LDA address,X is 4 cycles.
- The X register is now free for other uses. Without being monopolized as the data stack pointer, X can be put to use for all kinds of other things like loop counters. For example, incrementing X each time through a loop with INX is 2 cycles, while storing the counter on the data stack and incrementing it with INC counter,X is 6 cycles.
- No function overhead. The X register has to be adjusted to make room on the data stack each time a function is called. It takes 7 cycles to save the X register to the hardware stack at the beginning of the function and restore it at the end. It takes 2 more cycles for DEX for each byte of local variable used to adjust the data stack pointer.
- One type of local memory. With the traditional assembly macros I had to decide between using BYTE and WORD to reserve locals space on the X-indexed data stack or using ZPBYTE and ZPWORD to temporarily free up space in zero page for locals. I got this tradeoff wrong at least once when porting the game to traditional assembly. With the optimizer, all variables have the speed of ZPBYTE and ZPWORD without any overhead.
Consider this example function and how it is implemented in both versions of assembly:
;Traditional assembly
FUNC mult5 ;multiply a number by 5
ARGS
BYTE num
VARS
BYTE counter
END
LDA #5 ;loop counter
STA counter,X
LDA #0 ;product=0
.loop:
CLC
ADC num,X ;add number
DEC counter,X ;counter--
BNE .loop
MOV.B A,ret_val
END
|
;Optimized assembly
FUNC mult5 ;multiply a number by 5
ARGS
BYTE num
;Counter stored in X instead
END
LDX #5 ;loop counter
LDA #0 ;product=0
.loop:
CLC
ADC num ;add number
DEX ;counter--
BNE .loop
MOV.B A,ret_val
END
|
Here is the assembly output after macro expansion and assigning variable addresses:
;Traditional assembly
mult5:
PHX
DEX
DEX
LDA #5
STA 1,X
LDA #0
.loop:
CLC
ADC 0,X
DEC 1,X
BNE .loop
STA ret_val
STZ ret_val+1
PLX
RTS
|
;Optimized assembly
mult5:
;no stack adjustment overhead
LDX #5
LDA #0
.loop:
CLC
ADC 2 ;1 cycle faster
DEX ;4 cycles faster
BNE .loop
STA ret_val
STZ ret_val+1
;no stack restoration overhead
RTS
|
The optimized version is smaller and takes less cycles. This is especially important inside of loops where the cycles saved are much more important than the reduced function overhead.
After I had the optimizer and new NASM-based macros running, converting the traditional assembly version to this version was fairly straightforward. One interesting thing is that the traditional version only uses the X register for a data stack, so I didn’t have to change any of the game code that uses X for the optimized version to work. This is because none of the macros used for the optimized version ever touch X, so it stays the same in all functions, and the offsets supplied to all instructions accessing local variables are now the addresses assigned by the optimizer. Finding and eliminating all references to X in the optimized version saved a lot of cycles. Going back and replacing some counter variables with the newly free X sped up the optimized program by an additional 1%.
Porting the Game to C
Robot Game - Traditional assembly on GitHubThe first step of porting the game to C was getting the CC65 compiler up and running. The first four hours were fighting with the linker script and meaningless “Range error” messages before everything worked. From there, the porting went pretty smooth. One thing that definitely helped was the similarity in syntax to Python. Some sections of code could be copied in and run with minor syntax changes. Anything with dictionaries and lists, though, took a little longer to get working. It struck me how much the choice of language can affect the structure of a program. If I had written the program from scratch in C instead of Python, I don’t think it would look exactly like the C port from Python.
Some of the data, mainly for images, is stored in ROM in the memory between 0x4000 and 0xBFFF. This is the same window used by the program to access video memory, so the data and functions there aren’t available while the program is drawing to video memory. To get around this, the startup code copies a lot of image data out of ROM into the RAM from 0x200 to 0x3FFF so it will be accessible while the video memory is activated. This ROM also contains some routines, such as processing key presses, that can run with the screen memory disabled. The main ROM that starts at 0xC000 and this banked ROM that shares address space with the video memory are compiled as two separate modules and linked together. CC65 provides #pragma statements that make it very easy to switch code and data to another segment defined in the linker file. Figuring out what can run from this banked ROM with the graphics memory disabled was tricky and required a good bit of balancing to get everything to fit.
CC65 has some interesting optimization options that can be combined: -Oi and -Os increase inlining and -Or enables register variables which are stored in zero page. Register variables are prefixed by the keyword “register,” and they work essentially the same as the ZPBYTE and ZPWORD macros above that copy zero page memory to free it up for a function to use and restore it when the function ends. The same caveat applies here where you have to consider the overhead of copying to know which variables should be register variables. Comparing the generated assembly shows that these optimizations can save a lot of cycles! Even just -O does a lot of useful optimizing that really speeds up the code. Another handy feature is #pragma static-locals which stores local variables at a fixed location in main memory rather than on the stack.
One fun thing about this port was rewriting different sections of the code using different structures to see how it changes the size. Sometimes it made a big difference! The if/else structure that draws the stats for items shrunk by over 1.5 KB when I converted it to use a lookup table instead. The same type of optimization saved another 300 bytes in the code that draws the player stats. Those are significant savings considering the final program is only 27 KB.The main challenge of this port was just getting the compiler running and adjusted to the memory map of my system. One slightly annoying thing is that CC65 supports a version of C similar to C99, so some things I’m used to are missing. Functions that don’t take any parameters need “void” between the parentheses in the function declaration. Forgetting to add this just generates an error about conflicting types for the function, which is not very helpful. Declaring a variable inside of a loop is also not supported: for (int i=0;i<10;i++).
Porting the Game to Forth
Robot Game - Forth on GitHubThis port took way longer than the other three. The first step was to get Tali Forth 2 running on my simulator. This is a really impressive version of Forth that runs on a 65C02 and generates subroutine threaded code (STC), which is generally the fastest type of Forth code. Supporting the 65C02, not just the 6502, and outputting fast code make it a good fit for this project. SamCoVT on the 6502 forum helped me a lot customizing Tali Forth 2 to work for my setup. The main thing was removing a lot of unneeded functionality so there would be enough room for the game data. All of the words related to the built-in editor, disassembler, and input buffers were removed since I wasn’t writing the Forth code from inside the simulator. Later, when space was running low, I removed as many standard words as possible that weren’t used in the game.
At that point, I had a Forth prompt in the simulator I could use to define words:
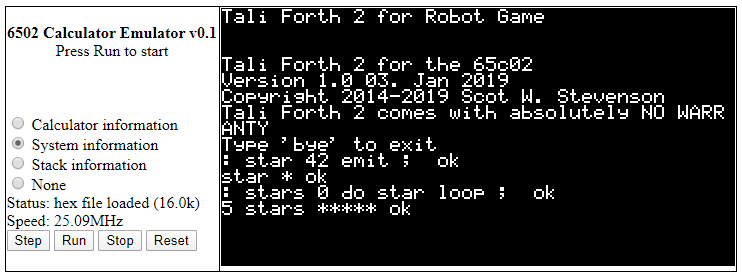
Tali Forth 2 running in browser-based 65C02 emulator
Of course, typing thousands of lines of source into this prompt to implement the game is not very practical, even with the help of the traditional block-based file system some Forths have. Instead, I wrote the source in a text file and had the simulator load each character of the file as a key press as if I had typed in the entire source every time the simulator starts. Towards the end of porting the game, it took about 9 seconds for the simulator to type the file in and compile it even with the simulator running at the equivalent of a 40-50 MHz 65C02. The version of the game on the website is a snapshot of memory after the entire source was typed in.
The first thing to port over was the list of 250 or so constants the game relies on. In C, this is a list of #define statements. Astonishingly, just defining these constants in Forth took up 7 KB of the 14.8 KB of available RAM! There definitely would not be enough room for the game data losing that much memory. Instead, I made a Python script to preprocess the code, note any constants or enumerations, and replace references to them with their values. This accomplishes the same goal as using constants in Forth, but doesn’t waste any memory on the target system.
As I started adding words to the program, the RAM started to fill up pretty quickly again. The name of each word is embedded in the word itself so that Forth can find it when new code references the word. This also takes up several KB of memory that would be better used for game data, so I had the Python script also shorten every word of the source not found in the built-in dictionary before outputting the file the simulator loads. For example, if the first word defined is “DrawMenuInventory,” the Python script would replace all references to “DrawMenuInventory” with “x1.” The next word would be recoded as “x2” and so forth. Here is an example of the script working on a short program:
\ before processing with script: 5 const increase_amount : increase increase_amount + ; 7 increase |
\ after processing with script: : x1 5 + ; 7 x1 |
Another way to reclaim scarce program space is to filter out variable names. Each version of the game has about 45 byte-long global variables that need to be available to all functions. The Forth version has another 47 byte-long global variables that are used temporarily by functions the same way locals are used in C and assembly. In fact, these variables are called “local” variables in Forth, even though they would be called globals in any other language. Permanently allocating those variables for the life of the program when most of them are used only occasionally by one function is very inefficient, but Forth doesn’t offer a good solution when a word needs access to temporary storage that doesn’t fit on the first three levels of the stack. Each variable declaration takes 13 bytes plus one byte for each character in the variable name, so the Forth version needs about 2 KB of memory for these 90 or so variables.
I got around this by adding a new word "var" to declare variables in conjunction with the Python script above. Any variable defined with var is assigned an offset starting with 0 by the script. After all the variables are defined, the script outputs Forth code to allot enough bytes for all the variables in one chunk and replaces any references to the variables with the literal address of the beginning of the variable block plus the offset assigned for that variable. Because you can use [ and ] to calculate the sum of the address and offset at compile time then insert it into the word with literal, the variable reference is reduced to just one pre-calculated address. Here’s an example:
\ before processing with script: begin_vars var foo var bar var baz end_vars baz c@ foo c! |
\ after processing with script: create varblock 3 allot [ varblock 2 + ] literal c@ [ varblock 0 + ] literal c! |
Because the calculation between [ and ] happens at compile time, the code is equivalent to the following if, for example, varblock is assigned address 1000:
create varblock 3 allot 1002 c@ 1000 c!
This system needs about 20 bytes to create varblock then exactly one byte per variable for the 90 or so global variables rather than 2 KB.
These three tools implemented in the Python script let me free up a large amount of memory and continue implementing the game. After a while, memory started to dwindle again since Forth (at least Subroutine Threaded Code) is very space hungry compared to C and assembly. Here is what the memory map looked like at that point:
RAM, where both the data and the compiled Forth code are stored, was almost full. Banks 2 and 3 were still empty. The challenge was to figure out which memory window to point those banks to in order to access them. At that point, the memory windows were configured like this:
Memory window 1 needs to always point to the RAM where data that needs to be visible at all times is stored, so that window can't be used to access banks 2 and 3. Bank 4 also needs to be available at all times since Forth words constantly jump back into the Forth runtime to execute built-in words. The only alternative left is memory windows 2 and 3 which normally point to video memory. Banks 2 and 3 can therefore hold any code or data that doesn't access video memory. To use the data there, the program temporarily changes those windows to point to banks 2 and 3 then points the windows back to video memory when it's done. Since those banks can't be enabled at the same time as video memory, the words stored there handle non-graphics tasks like loading the game, reacting to key presses, and processing game logic. This takes up all but 2 KB of the 32 KB in those two banks, and the three menu screens still needed to be implemented.
The source code is organized by function rather than everything that goes into bank 1 followed by everything that goes into bank 2 and 3. This means that Forth has to switch between putting new words and data in the two sections of memory. Luckily, there are a few words provided to create two different word lists at different addresses and switch between them. It took a lot of tinkering to get this working reliably.
The three menu screens still needed to be implemented and the only space left was the 5 KB or so in bank 4 after Tali Forth 2, which was not nearly enough room. The solution was to copy the entire 11 KB Forth installation to several banks so that pointing memory window 4 to one of them would give me an extra 5 KB of space to work with while still being able to access the core Forth words. In addition to one bank for each menu screen, I needed one bank for code common to all menus and one for game code that wouldn't fit into bank 1. Here's the layout:
One thing I did to keep track of the space left in each bank as I juggled which piece of code goes where was to use the code pointers to show how much space was left in each bank every time the game starts:
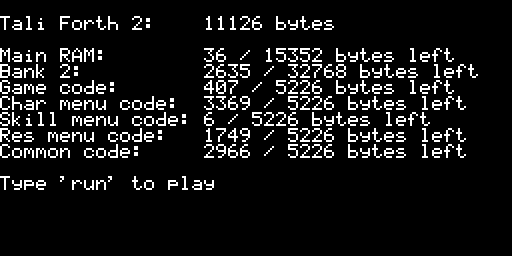
Memory usage of Tali Forth 2 port of Robot Game
With everything working correctly, I set the built-in variable strip-underflow to true so that Tali Forth 2 would not insert code to check for stack underflows. This made the game noticeably faster and reduced the size. Another thing I changed is the nc-limit variable which determines the max sized word that will be inlined. Bumping this up to 0x26 took up some of the extra space and hopefully makes the game a little faster. (Setting it to 0x27 causes the game to crash.)
Programming in Forth was deeply frustrating, but it does have some bright spots. Being able to exit the game loop and return to the Forth prompt to see the stack and investigate memory interactively was a big plus. One word I relied on heavily would use .s to print the stack then execute a BRK instruction which would stop the simulator. This let me see the stack at each step of a process in a way that is not really possible with C for the 65C02. Another nice thing is using the counter variables i and j with DO loops since you don't have to declare them or think of names for them. I also liked that searching for : in the source let's you jump immediately to a word definition, whereas this takes a little more searching in C.
Here are a few utility words that were useful:
: 3drop 2drop drop ; : 3dup 2 pick 2 pick 2 pick ; : >>r r> -rot >r >r >r ; compile-only : >>>r r> swap >r -rot >r >r >r ; compile-only : r>> r> r> r> rot >r ; compile-only : r>>> r> r> r> rot r> swap >r ; compile-only : 0>= dup 0= swap 0> or ; : c@+1 dup c@ 1+ swap c! ; : c@-1 dup c@ 1- swap c! ; : @+1 dup @ 1+ swap ! ; : @-1 dup @ 1- swap ! ;
The return stack juggling words like r>> and r>>> may seem a little strange. This brings us to one of the main shortcomings of Forth. If you need to access more than three local variables at once (in the body of a loop for example) there is just no convenient way to do so. One thing you can do is stash several of the top level variables on the return stack then restore them when you're done, which is why r>> and r>>> exist. Some Forthers say this is bad style, and it is tedious and slow to keep up with. After a while, I gave in and switched to using global variables for this purpose. Some Forth users have told me that needing to access more than three variables at once doesn't really happen, but this was absolutely not true even in a very small project like mine. Consider the variables used in this C function that draws 1 bit-per-pixel images with optional rounded corners:
int DrawTile1bpp(unsigned char tile, unsigned char x, unsigned char y,
unsigned char color1, unsigned char color2)
{
register unsigned char *gfx_ptr=CalcXY(x,y);
register const unsigned char *tile_ptr=tiles[tile];
register unsigned char bit_count, byte_count;
register unsigned char row_count, t_height, t_width;
register unsigned char t_pixel, edge_style;
unsigned char t0,t1,t2,t3,trans_row,skip_pixel=false;
...
}
The tile, x, and y arguments are used to calculate pointers, but the other two arguments and all 15 local variables need to be accessible every iteration through the loop that draws the pixels. Even for a very simple function like this, there is just no way to juggle 17 variables in a loop in Forth that isn't awkward.
Another disadvantage is that the stack has to be reorganized at the end of every loop body to put it back in the order it was when the loop body began. This gets really complicated with a deeper stack and nested loops. It seems so strange to waste brain power on something the compiler should take care of for you, not to mention how many cycles this rearranging wastes. This is especially annoying when you need to modify the code inside of a loop and introduce a new variable. Most or all of the stack juggling code needs to be rewritten in that case since the stack now looks different.
The chief annoying thing is how unreadable the code turns out to be. Consider this short Forth program:
foo bar baz
Without parenthesis or commas, there is no way to tell just by looking at the code which of those are functions, which ones are variables, which of them are inputs to the others, or what any of them return. Forth fans will say that that information is available in the stack comment for the word's declaration, but that assumes that the programmer bothered to create one. Even if they did, you have to search in several places in the file to figure out what is instantly obvious if the same code were written in a language like C or Python. It's easy to see why people criticize Forth for being "write only." If you translated the line above into C, it could be doing any of the following:
|
|
There was one bug that kept reoccurring that took a long time to track down. Compiling this line caused Forth to jump to unitialized memory and crash:
map_data + c@ MAP_ROCK <> \ return true or false
The bizarre thing is that all of these lines worked fine:
map_data + c@ MAP_ROCK <> \ return true or map_data + c@ MAP_ROCK <> \ return true or fals map_data + c@ MAP_ROCK <> \ return true or false0
Each time a line is typed in, Forth searches its dictionaries for each item on the line. Searching the built-in dictionary, main dictionary in RAM, secondary dictionary in banks 2 and 3, and whichever dictionary is enabled in bank 4 takes many cycles, so it's not practical to compare the working and non-working versions above side by side to see what causes the crash. Instead, I output the status of the processor on every instruction to a text file. This showed that the working version executes about 27,000 cycles, while the version that crashes executes about 67,000 and trashes the memory. Comparing the two text files with a text diff program called WinMerge helped me pinpoint where the two versions diverged. It seems the dictionaries for the editor, block system, and disassembler were still enabled even though they pointed to memory where there was no dictionary since those words had all been removed. When Forth tried to look up a word, it would start searching at the address where it expected the dictionaries and treat the data there as a linked list. This caused the lookup mechanism to go bouncing around memory as the next address in the linked list is random data. It stops searching when the next link points to address 0x0000, which in this case only happens accidentally. The problem in the example above was that the random bouncing around landed on the variable that holds the length of the string entered, so the next random address in the linked list was different for each line above. Disabling the three missing dictionaries fixed the problem.
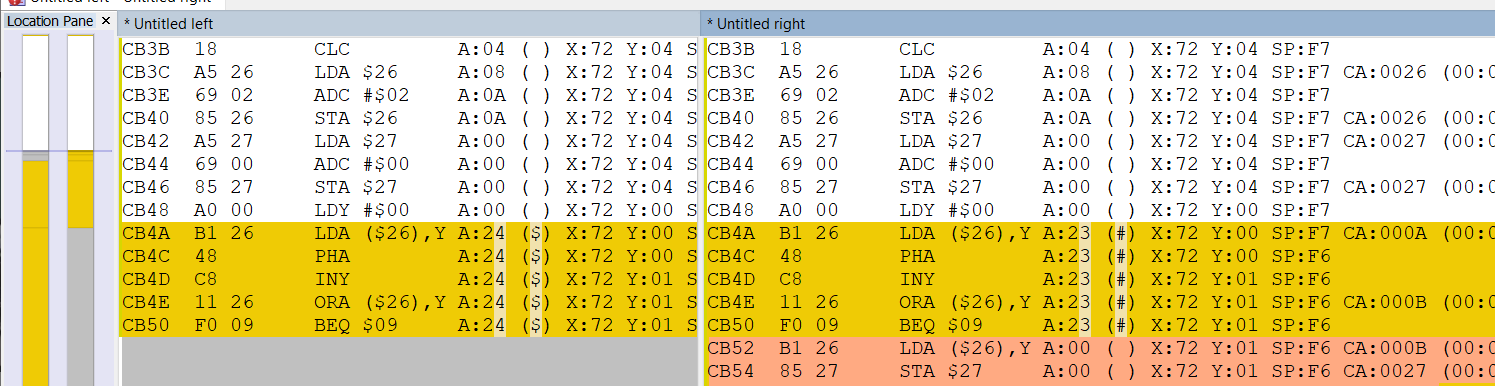
Comparing executed cycles in WinMerge to pinpoint crash
Results
With all four ports finished, I could start comparing the speed of the four versions. It's not really possible to boil down the performance of each version to one number, since the difference in speed varies by task and user input, so I identified some tasks that I could time and compare:
- CopyTile - Copy one tile to another
- ColorTile - Ground. Color in a tile based on list of colors
- RotateTile - Rotate a tile by 90 degrees
- DrawTile - Crystal
- DrawTile - Rock
- DrawTile - Enemy robot
- DrawTile - Player robot
- DrawTile1bpp - HP heal
- DrawTile1bpp - Main selector
- DrawTile1bpp - Item selector
- DrawTile1bpp - Skill 1
- rand - Generate a pseudo-random 16-bit number
- rand8 - Divide 16-bit pseudo-random number by 8-bit divisor and return remainder
- FillMap - Fill the monster or character map with a value
- MakeMap - Construct the map and place monsters and crystals
- LoadMonsters - Place monsters randomly on map
- clrscr - Fill the screen with one color
- DrawFrame - Draw the play field
- DrawText - Draw text on right side of game screen for HP, Battery, and Experience
- DrawBar - Draw status bars on right side of game screen for HP, Battery, and Experience
- Draw minimap - Draw the minimap on the legend
- DrawLegend - Draw the game legend
- CalcStats - Calculate robot stats based on items equipped and skills enabled
- ColorHero - Color in robot based on items equipped
- DrawItemStats - Draw stats for item in menu
- DrawInventory - Draw inventory of character screen
- DrawSkills - Draw skills menu
- DrawResourcesDraw resources menu














First, I calculated how many cycles each of these tasks took in traditional assembly and used that as a baseline. The number of cycles those tasks took in the other three ports is given in relation to the baseline. Numbers greater than 100% are faster than traditional assembly and numbers less than 100% are slower. A rating of 20%, for example, would be 5 times slower than the baseline.
| Task | Trad asm (baseline) | Optimized asm | CC65 C compiler | Tali Forth 2 |
|---|---|---|---|---|
| CopyTile - Ground_raw | 100% | 109.14% | 17.14% | 6.53% |
| ColorTile - Ground_0 | 100% | 101.71% | 21.96% | 6.76% |
| RotateTile | 100% | 104.71% | 12.55% | 2.13% |
| DrawTile - Crystal | 100% | 101% | 48.64% | 6.33% |
| DrawTile - Rock | 100% | 101.73% | 31.24% | 7.08% |
| DrawTile - Monster | 100% | 101% | 43.74% | 6.46% |
| DrawTile - Robot | 100% | 101.04% | 49.66% | 6.38% |
| DrawTile1bpp - HP heal | 100% | 111.97% | 83.18% | 5.42% |
| DrawTile1bpp - main selector | 100% | 111.79% | 85.6% | 7.06% |
| DrawTile1bpp - item selector | 100% | 112.11% | 83.52% | 6.88% |
| DrawTile1bpp - Skill 1 | 100% | 111.53% | 83.82% | 5.28% |
| rand | 100% | 100% | 32.7% | 6.14% |
| rand8(5) | 100% | 110.19% | 151.81% | 2.55% |
| FillMap | 100% | 101.39% | 17.41% | 25.07% |
| MakeMap | 100% | 110.04% | 116.93% | 30.19% |
| LoadMonsters | 100% | 110.15% | 39.79% | 27.42% |
| clrscr | 100% | 100.17% | 17.83% | 25.09% |
| DrawFrame | 100% | 103.15% | 36.89% | 6.93% |
| DrawText on legend | 100% | 106.71% | 37.32% | 5.52% |
| DrawBar on legend | 100% | 112.78% | 26.21% | 24.72% |
| Draw minimap | 100% | 110.61% | 86.63% | 27.97% |
| DrawLegend | 100% | 109.91% | 53.47% | 22.89% |
| CalcStats | 100% | 126.3% | 24.84% | 7% |
| ColorHero | 100% | 101.82% | 23.08% | 3.85% |
| DrawItemStats | 100% | 106.17% | 36.59% | 5.44% |
| DrawInventory | 100% | 104.59% | 37.56% | 8.05% |
| DrawSkills | 100% | 110.25% | 53% | 6.43% |
| DrawResources | 100% | 108.13% | 32.04% | 7.81% |
Here's a graph of the above data:
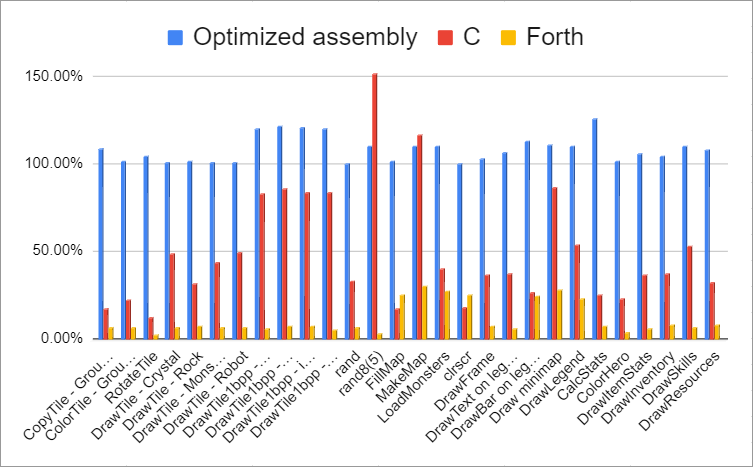 First set of results comparing perfromance of languages
First set of results comparing perfromance of languages
Right away it's clear that the optimized assembly gives a decent speed boost in most cases. C is 20-80% as fast as traditional assembly with a few exceptions, and Forth is about 5-25% as fast. Averaging these numbers for each language wouldn't make sense because some of these functions are called much more often than others, so their true effect on average gameplay is difficult to gauge.
There are a few interesting points on the graph. The first is the four calls to DrawTile1bpp where the optimized assembly version is much faster than traditional assembly while the C version is almost as fast as the traditional assembly version. This suggests that there is a problem in the traditional assembly port I'm using as a baseline, not that the optimized assembly and C versions are faster than normal for this function. Here are the variable declarations for that function in traditional assembly:
FUNC DrawTile1bpp
ARGS
BYTE tile, xpos, ypos, color1, color2
VARS
ZPWORD gfx_ptr,tile_ptr
BYTE t_width,t_height,edge_style
BYTE row_count,byte_count,bit_count
BYTE t_pixel,skip_pixel,trans_row
BYTE t0,t1,t2,t3
END
...
END
As I explained above, declaring a variable with ZPBYTE or ZPWORD assigns it to a static address in zero page, meaning there is no overhead to access the variable, but there is a large amount of overhead for the variable when the function starts. Variables declared with BYTE and WORD are the opposite since there is overhead every time the variable is accessed but much less overhead when the function begins. Since the main speed up of optimized assembly comes from eliminating both the access overhead and the setup overhead, that must be where the speed difference comes from. As you can see above, most of the variables are declared with BYTE. We can compare this to the declaration of the function in C:
int DrawTile1bpp(unsigned char tile, unsigned char x, unsigned char y,
unsigned char color1, unsigned char color2)
{
register unsigned char *gfx_ptr=CalcXY(x,y);
register const unsigned char *tile_ptr=tiles[tile];
register unsigned char bit_count, byte_count;
register unsigned char row_count, t_height, t_width;
register unsigned char t_pixel, edge_style;
unsigned char t0,t1,t2,t3,trans_row,skip_pixel=false;
...
}
Mystery solved! Most of these variables have the "register" prefix, which means they should be declared as ZPBYTE instead of BYTE in the assembly version to get the same speed up. Making this change and removing the ",X" from references to those variables brings the advantage of optimized assembly from an extra 20-21% to only 11-12% which is more in line with the other gains from optimizing. I also checked that the variable types matched between the assembly and C versions for all other functions. Here is a new graph to reflect what the performance would have looked like if I hadn't picked the wrong type of variable:
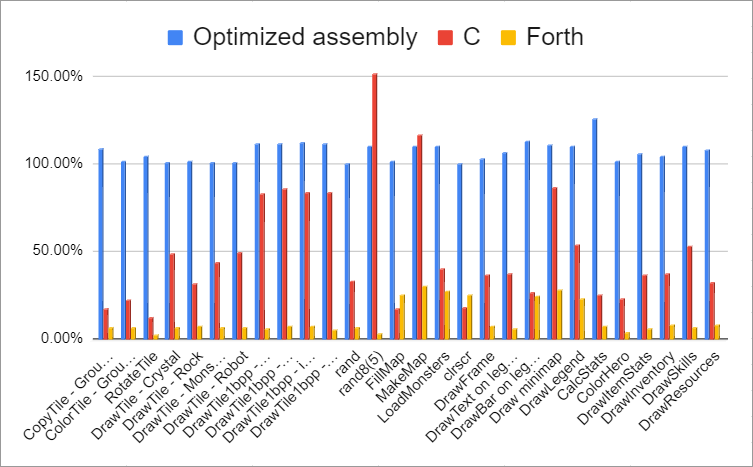 Corrected results comparing performance of languages
Corrected results comparing performance of languages
This illustrates one of the disadvantages of traditional assembly I mentioned above. It's not hard to choose the wrong type of local variable on accident, while there is only one type in optimized assembly, so you never make that mistake.
The other interesting point on the graph is that C was much faster than traditional assembly for the rand8 and MakeMap functions. rand8 divides a 16-bit value generated by the random number generator by an 8-bit argument and returns the remainder. One way to do this is to convert the 8-bit divisor to a 16-bit value then multiply it by 2 repeatedly until it reaches the same magnitude as the numerator before subtracting and shifting. For example, imagine the random number generator produced the hex number 0x9876 and the rand8 function divided this by 5 to use the remainder as a random number between 0 and 4. First, the 8-bit divisor of 5 should be shifted left 4 times and moved to the high byte yielding the 16-bit value 0x5000. Then this number can be repeatedly subtracted and shifted from the numerator of 0x9876 to perform division. I got lazy with the assembly version and decided to just subtract the 8-bit divisor from the high byte of the 16-bit numerator to avoid having to convert the divisor to 16 bits. In this example, it would subtract 5 repeatedly from 0x98, the high byte of 0x9876, until it underflows, which would be 31 times. This is much less efficient than shifting. The C source for division uses a slightly different strategy by converting the numerator to 24 bits rather than the divisor to 16 bits before shifting, which is more efficient than both my method and the shortcut. As a result, the C versions of rand8 and MakeMap, which calls rand8 many times, are much faster. The lesson here is that assembly is only faster than C if it's well-written.
Size and Time to Implement
Size is a little tricky to compare across versions in a consistent way. The C port of the game stores game resources like tiles in the simulated ROM and copies them to simulated RAM at startup. After I finished the port, I realized that the linker could just place that data directly in RAM without having to copy anything the way a real system does. That means there are two copies of that data at runtime and each copy takes up about 13.3 KB. The combined code plus data for the port is 40 KB, which would be around 27 KB if I had put the tiles directly in RAM.
Forth is also a little tricky because the Forth installation contains not just the runtime but everything needed to evaluate and compile new words. Since there is no way to remove the compiling parts after the game is finished, I'm counting them as part of the size the game takes up. As mentioned above, I had to copy the Forth installation across five different banks, but I'm only counting the size once since the copies might be avoided with different banking hardware. The size of Forth is also inflated by at least 1 KB since it includes global variables unlike the other versions.
I timed how long each port took, although the times aren't representative for each language. For one, this is the first non-trivial Forth program I've written, so it took a long time partly due to my inexperience. I didn't count time for tasks that had to be done once but won't have to be done again for the next project in that language like writing assembly macros or figuring out how the CC65 linker script works. The order of porting also matters, since I got more used to reimplementing everything with each port. It also made sense to port from Python to C first then port the C to assembly. It would have taken a lot longer to convert Python directly to assembly.
| Language | Size | Port time |
|---|---|---|
| Traditional assembly | 24.3 KB | 70 hours |
| Optimized assembly | 23.5 KB | - |
| C | 27 KB | 60 hours |
| Forth | 69.1 KB | 152 hours |
(The optimized assembly version is very similar to the traditional assembly but was compiled with different tools rather than being ported from scratch, so no time is given.)
Code Analysis: rand
This function generates a 16-bit pseudo-random number based on the last generated number. (As mentioned above, I made a mistake porting this from C to assembly.) This is the one example in the results where there is no difference between the traditional and optimized assembly versions, since the function does't use local variables. Here's the code in C and Forth:
void rand()
{
rand_val^=rand_val<<7;
rand_val^=rand_val>>9;
rand_val^=rand_val<<8;
}
|
: rand ( -- rand_val ) rand_val @ dup 7 lshift xor dup 9 rshift xor dup 8 lshift xor dup rand_val ! ; |
The C version takes about three times as many cycles as the baseline assembly version. Here is the optimized assembly that CC65 outputs with added line numbers:
001. ;rand_val^=rand_val<<7; 002. lda _rand_val 003. ldx _rand_val+1 004. jsr shlax4 005. jsr shlax3 006. eor _rand_val 007. pha 008. txa 009. eor _rand_val+1 010. tax 011. pla 012. sta _rand_val 013. stx _rand_val+1 014. ;rand_val^=rand_val>>9; 015. sta ptr1 016. stx ptr1+1 017. lda _rand_val+1 018. lsr a 019. eor ptr1 020. pha 021. lda #$00 022. eor ptr1+1 023. tax 024. pla 025. sta _rand_val 026. stx _rand_val+1 027. ;rand_val^=rand_val<<8; 028. sta ptr1 029. stx ptr1+1 030. lda #$00 031. eor ptr1 032. pha 033. lda _rand_val 034. eor ptr1+1 035. tax 036. pla 037. sta _rand_val 038. stx _rand_val+1 039. rts
Lines 2 and 3 load the 16-bit rand_val using the 8-bit registers A and X as a pair. There are no instructions that treat them as a pair, but the compiler groups internally that way. shlax4 and shlax3 on the next two lines rotate the value in the two registers by 4 and 3 bits respectively. It's good that the optimizer realizes that we're rotating by a constant value and uses different code to speed up the rotation. Unfortunately, it doesn't take the shortcut of rotating right once and copying the low byte to the high byte. Lines 6-11 XOR the shifted value with the old rand_val using A and X again as a 16-bit pair. This could be more efficient by writing the low byte directly to rand_val after the calculation on line 6 rather than waiting until line 12. This would eliminate lines 7, 10, and 11.
The translation of the next line of C starts by storing the value from the calculation on the previous line, which makes sense because rand_val is reused. (ptr1 is being used here as temporary storage not just a pointer.) In this case, the optimizer does recognize that a 9-bit shift right can be replaced by a single shift right then moving the high byte to the low byte. As it turns out, the calculation does not need the cached value stored in ptr1 since it could just use rand_val, so lines 15 and 16 are unnecessary. I assume it defaulted to storing the value in ptr1 temporarily since rand_val is assigned a value calculated from its previous value which could require temporary storage depending on the calculation. Lines 19-24 perform a 16-bit XOR like lines 6 and 11 above, so they could also be optimized eliminating lines 20, 23, and 24. Another optimization would be to replace lines 21 and 22 with simple "lda ptr1+1" since XORing something with 0 doesn't do anything.
The last line of C code also unnecessarily caches A and X, performs an unnecessarily long 16-bit XOR, and XORs one byte with 0, so the same improvements apply here as to the above two lines.
The Forth version takes 16 times as many cycles as the assembly versions and over five times as many as the C version. Here's the code from Tali Forth 2 for the words dup, xor, and lshift (rshift is identical except shift direction):
001. xt_dup: 002. jsr underflow_1 003. 004. dex 005. dex 006. 007. lda 2,x ; LSB 008. sta 0,x 009. lda 3,x ; MSB 010. sta 1,x 011. 012. rts 013. 014. xt_xor: 015. jsr underflow_2 016. 017. lda 0,x 018. eor 2,x 019. sta 2,x 020. 021. lda 1,x 022. eor 3,x 023. sta 3,x 024. 025. inx 026. inx 027. 028. rts 029. 030. xt_lshift: 031. jsr underflow_2 032. 033. ; max shift 16 times 034. lda 0,x 035. and #%00001111 036. beq _done 037. 038. tay 039. 040. _loop: 041. asl 2,x 042. rol 3,x 043. dey 044. bne _loop 045. 046. _done: 047. inx 048. inx 049. 050. rts
Line 2 jumps to a small piece of code that checks to make sure there is at least one item on the stack. One of the neat things about Tali Forth 2 is that you can set it to leave out these checks in compiled words to save time and space. Lines 4 and 5 make some room on the stack for the 16-bit value being duplicated. Notice how all of these words change the stack size, while C and traditional assembly only adjust the stack at the beginning and end of a function. This constant stack resizing is one of several reasons why Forth is so inefficient.
Like in dup, the addresses of 0-3 used in xor are all stack offsets. Since there is only one version of each word, there is no way to tailor the underlying assembly like the C opitmizer does. This means xor blindly works on the top two 16-bit values even if it's obvious at compile time that part of the calculation could be omitted if one of the bytes is zero. lshift and rshift have the same problem. The check on lines 33-36 always takes place even if it works on a constant known at compile time, as is the case for all three shifts in rand. The same goes for the loop on lines 40-44, which is written for the slowest case where the number of bits to shift is not known until run time. Shifting by a constant number of bits in Forth is just as slow as shifting by a variable number. All of these inefficiences combine to make the Forth version much slower than the others.
Code Analysis: CalcStats
This function calculates the player's stats by looping through the equipped items and applying stat bonuses from them. The optimized assembly version is 26% faster than the traditional assembly version, but at only 924 cycles, a lot of the advantage comes from avoiding the overhead of setting up variables. The C version takes about four times as long as the traditional assembly version. The whole function is kind of long, so here's the interesting part of the C version that loops through the equipped items:
001. for (i=0;i<SLOT_COUNT;i++)
002. {
003. for (j=0;j<item_stats[hero_equipped[i]][stat_count];j++)
004. {
005. stat_ID=item_stats[hero_equipped[i]][stat_begin+j*2];
006. stat_ptr=stat_pointers[stat_ID];
007. ...
008. }
009. }
Line 1 loops through the robot's five slots. hero_equipped on line 3 has one byte for each slot and holds the item ID of the item equipped. item_stats is a 2D array that uses the item ID as an index where each row holds bytes describing the item. stat_count is part of an enum that identifies the byte in the row indicating how many stat bonuses the item has. In other words, line 3 loops through all of the stats of the item equipped in the slot specified by the loop on line 1. Line 5 works similarly but instead of pointing to the count of stats on the item, it skips ahead to the pairs of bytes describing the bonuses where the first byte is the stat bonus ID and the second bye is the bonus amount. Line 6 uses the fetched stat bonus ID to index into a list of pointers to the variables that hold the player's stats which the bonuses apply to. The next line (not shown) loads the byte after the byte loaded on line 5, which is the value to be added to the stat variable pointed to by the variable from line 6.
Here is the assembly generated by the C compiler:
001. ;for (i=0;i<SLOT_COUNT;i++)
002. ;{
003. lda #$00
004. ldy #$07
005. L2C7C: sta (sp),y
006. cmp #$05
007. jcs L2C77
008. ;for (j=0;j<item_stats[hero_equipped[i]][stat_count];j++)
009. ;{
010. lda #$00
011. dey
012. L2C7E: sta (sp),y
013. lda (sp),y
014. jsr pusha0
015. ldy #$09
016. lda (sp),y
017. tay
018. lda _hero_equipped,y
019. asl a
020. bcc L2C67
021. ldx #$01
022. clc
023. L2C67: adc #<(_item_stats)
024. sta ptr1
025. txa
026. adc #>(_item_stats)
027. sta ptr1+1
028. ldy #$01
029. lda (ptr1),y
030. tax
031. lda (ptr1)
032. sta ptr1
033. stx ptr1+1
034. ldy #$04
035. lda (ptr1),y
036. jsr tosicmp0
037. jcs L25A3
038. ;stat_ID=item_stats[hero_equipped[i]][stat_begin+j*2];
039. ldy #$07
040. lda (sp),y
041. tay
042. ldx #$00
043. lda _hero_equipped,y
044. asl a
045. bcc L2C68
046. inx
047. clc
048. L2C68: adc #<(_item_stats)
049. sta ptr1
050. txa
051. adc #>(_item_stats)
052. sta ptr1+1
053. ldy #$01
054. lda (ptr1),y
055. tax
056. lda (ptr1)
057. sta ptr1
058. stx ptr1+1
059. ldx #$00
060. ldy #$06
061. lda (sp),y
062. asl a
063. bcc L2C69
064. inx
065. clc
066. L2C69: adc #$05
067. bcc L2C6A
068. inx
069. clc
070. L2C6A: adc ptr1
071. sta ptr1
072. txa
073. adc ptr1+1
074. sta ptr1+1
075. lda (ptr1)
076. ldy #$03
077. sta (sp),y
078. ;stat_ptr=stat_pointers[stat_ID];
079. ldx #$00
080. lda (sp),y
081. asl a
082. bcc L2C6B
083. inx
084. clc
085. L2C6B: adc #<(_stat_pointers)
086. sta ptr1
087. txa
088. adc #>(_stat_pointers)
089. sta ptr1+1
090. ldy #$01
091. lda (ptr1),y
092. tax
093. lda (ptr1)
094. ldy #$04
095. jsr staxysp
096. ...
097. ;}
098. L25AB: ldy #$06
099. lda (sp),y
090. ina
101. jmp L2C7E
102. ;}
103. L25A3: ldy #$07
104. lda (sp),y
105. ina
106. jmp L2C7C
107. L2C77:
Lines 3-5 initialize the local variable i used in the for loop to 0. The y register is used here as the offset into the locals stack rather than the x register used in the assembly and Forth versions. The advantage of this is that the stack doesn't have to fit into the 256 bytes of zero page memory since the pointer sp here is 16 bits. (Note that sp here is a pointer variable in zero page created by CC65, not the hardware stack pointer!) The disadvantage of using y instead of x for the stack pointer is the loss in speed. While the equivalent STA 7,X used in the assembly versions of the game takes 4 cycles, lines 4-5 of the C version take 8 cycles. Line 6 compares the loop variable to 5, and the jcs on line 7 is a macro to conditionally jump out of the loop if the end value has been reached. Lines 103-105 increment i at the end of the loop body and jump back to the top. Here too the offset into the stack has to be reloaded, so lines 103-104 take 7-8 cycles rather than the 4 of LDA 7,X in the assembly version.
The dey on line 11 changes the stack offset to 6 to point to j, which is one cycle faster than LDY #6. Line 12 updates j, so line 13 seems redundant. The pusha0 routine on line 14, which pushes j as a 16-bit value to the y-based data stack, is a lot slower than the equivalent x-based stack routine, but as mentioned above, this allows the stack to be larger than 256 bytes. Line 15 fetches i to index into hero_equipped on line 18. The offset for i is now 9 instead of 7 to account for the 16-bit value pushed on the stack on line 14. Lines 19-27 calculate a pointer to the desired element of item_stats by calculating a 16-bit pointer, which is much slower than accessing item_stats using y as an 8-bit offset with LDA item_stats,Y. The pointer version is necessary when item_stats is larger than 255 bytes, but it's clear at compile time that it's only 62 bytes, so this could be optimized. Lines 30-35 index 4 bytes into the selected element of item_stats to fetch the count of stats on the item. tosicmp0 compares the value of j pushed on the stack on line 14 to the stat count on the item and drops the value from the stack, which is slow because both values are promoted to 16 bits. The end of the loop body on lines 98-101 show that the stat_count is recalculated each iteration even though it never changes, which probably accounts for a lot of the speed difference.
The pointer calculation for lines 39-77 is similar to the calculation on 10-37. It's significant here that the pointer is recalculated each iteration here too even though at least the calculation of item_stats[hero_equipped[i]] doesn't change in the inner loop. For the next line of C, stat_ID is reloaded into A on line 80 even though line 77 shows that it's already loaded. Lines 81-93 calculate a 16-bit pointer for the desired element of stat_pointers, which could be an 8-bit offset like item_stats since stat_pointers is only 28 bytes. staxysp on line 95 writes the calculated value to stat_ptr.
Here's the optimized assembly version side by side with the assembly from the C compiler:
001. ;for (i=0...
002. ;{
003. lda #$00
004. ldy #$07
005. L2C7C: sta (sp),y
006. cmp #$05
007. jcs L2C77
008. ;for (j=0...
009. ;{
010. lda #$00
011. dey
012. L2C7E: sta (sp),y
013. lda (sp),y
014. jsr pusha0
015. ldy #$09
016. lda (sp),y
017. tay
018. lda _hero_equipped,y
019. asl a
020. bcc L2C67
021. ldx #$01
022. clc
023. L2C67: adc #<(_item_stats)
024. sta ptr1
025. txa
026. adc #>(_item_stats)
027. sta ptr1+1
028. ldy #$01
029. lda (ptr1),y
030. tax
031. lda (ptr1)
032. sta ptr1
033. stx ptr1+1
034. ldy #$04
035. lda (ptr1),y
036. jsr tosicmp0
037. jcs L25A3
038. ;stat_ID=...
039. ldy #$07
040. lda (sp),y
041. tay
042. ldx #$00
043. lda _hero_equipped,y
044. asl a
045. bcc L2C68
046. inx
047. clc
048. L2C68: adc #<(_item_stats)
049. sta ptr1
050. txa
051. adc #>(_item_stats)
052. sta ptr1+1
053. ldy #$01
054. lda (ptr1),y
055. tax
056. lda (ptr1)
057. sta ptr1
058. stx ptr1+1
059. ldx #$00
060. ldy #$06
061. lda (sp),y
062. asl a
063. bcc L2C69
064. inx
065. clc
066. L2C69: adc #$05
067. bcc L2C6A
068. inx
069. clc
070. L2C6A: adc ptr1
071. sta ptr1
072. txa
073. adc ptr1+1
074. sta ptr1+1
075. lda (ptr1)
076. ldy #$03
077. sta (sp),y
078. ;stat_ptr=...
079. ldx #$00
080. lda (sp),y
081. asl a
082. bcc L2C6B
083. inx
084. clc
085. L2C6B: adc #<(_stat_pointers)
086. sta ptr1
087. txa
088. adc #>(_stat_pointers)
089. sta ptr1+1
090. ldy #$01
091. lda (ptr1),y
092. tax
093. lda (ptr1)
094. ldy #$04
095. jsr staxysp
096. ...
097. ;}
098. L25AB: ldy #$06
099. lda (sp),y
090. ina
101. jmp L2C7E
102. ;}
103. L25A3: ldy #$07
104. lda (sp),y
105. ina
106. jmp L2C7C
107. L2C77:
|
MOV.B #0,item_counter .cs.loop: LDY item_counter LDA hero_equipped,Y ASL TAY LDA item_stats,Y STA item_ptr LDA item_stats+1,Y STA item_ptr+1 LDY #stat_count LDA (item_ptr),Y STA stat_max LDX #0 .cs.stats: TXA ASL ADC #stat_begin TAY LDA (item_ptr),Y PHY STA stat_ID ASL TAY LDA stat_pointers,Y STA stat_ptr LDA stat_pointers+1,Y STA stat_ptr+1 ... INX CPX stat_max JNE .cs.stats INC item_counter LDA item_counter CMP #SLOT_COUNT JNE .cs.loop |
Finally, here is the Forth implementation of the selected lines of CalcStats, which is 14 times slower than traditional assembly:
001. : ID>stat ( itemID -- item_addr ) 002. 2* item_stats + @ ; 003. 004. : LoadItemStats ( itemID -- ) 005. \ shortcut - all 11 variables stored contiguously 006. ID>stat item_type B move ; 007. 008. 5 0 \ 5 equipped slots 009. do 010. hero_equipped i + c@ \ itemID 011. LoadItemStats 012. item_stat_count c@ 013. 0 do 014. item_stat1 i 2* + dup c@ \ stat1_ptr stat1ID 015. swap 1+ c@ swap dup 2* \ stat1_x stat1ID stat1ID*2 016. [ EnableCharMenuROM ] 017. stat_pointers 018. [ EnableGameROM ] 019. + @ dup \ stat1_x stat1ID stat_ptr stat_ptr 020. ... 021. loop 022. loop
Forth programs are supposed to be divided up into many small words that are no longer than a few lines, which is why ID>stat and LoadItemStats are factored out here. Jumping in and out of these words can slow the program down, so thankfully Tali Forth 2 will inline any words shorter than a maximum size you can adjust. ID>stat converts an item ID to the address held in item_stats where information about the item starts. LoadItemStats uses that word to copy all 11 bytes of information about an item to 11 global variables set aside for the purpose. item_type is given as the starting destination address for the copy since it's the first of the 11 variables. In C, it wouldn't be safe to assume that variables declared together are stored in order in memory, but because Forth gives you lower level control, you can take some shortcuts like this.
Lines 8 and 9 loop through all five equipment slots like the outer for loop in the C version. Line 10 fetches the ID of the item equipped in each slot and passes that to LoadItemStats on line 11. One of the 11 variables the word fills in is item_stat_count fetched on the next line which is used for the loop on line 13. item_stat1 is the first stat of the item and the beginning point for stepping through the stat pairs on line 14. You can see on this line that I started adding comments to keep track of the stack.
Without showing the assembly for the words on line 15, you can imagine some of the inefficiency going on there. swap puts the pointer to the current stat on top of the stack so it can be incremented by one then used as a pointer to fetch a byte that is then swapped back to the second level of the stack. In assembly, both swaps could be eliminated because data at any address can be incremented, not just what's on top of the stack. Also, incrementing and dereferencing could be combined to save a few cycles rather than the two step process of 1+ c@. The pointer calculation here is also automatically 16 bits even if one of the much faster 8-bit offset modes mentioned above would have worked.
Line 16 enables the dictionary for the character menu ROM where stat_pointers is stored. Because this comes between [ and ], it's only executed at compile time long enough for Forth to find the address of stat_pointers before switching back to using the main game ROM on line 18. This is a neat feature that was pretty handy and also helps with calculating constants at compile time. Line 19 combines the address of stat_pointers with the index calculated on line 15 to generate stat_ptr.
Conclusions
Some conclusions I came to doing this project:
Assembly
- Optimzing 65C02 assembly with Python is a viable strategy. The speed gains from optimizing are modest at 5-10% in most of the cases tested, but that's enough of a boost to continue using it for future projects.
- There isn't much room for further optimizing hand-written assembly code. This would be the second goal for the optimizer in addition to managing zero page memory. After finishing this project, it seems like the main advantage would be finding redundant instructions like CLC which would offer a negligible increase in speed.
- Assembly macros are much more powerful than I knew. I had tried several times to find an efficient way to manage local variables and finally figured it out with this project.
- As stated above, there are pitfalls to assembly that don't exist in C and Forth. Assembly code can be less efficient than those languages if it's not well-written.
C
- CC65 does a pretty good job of optimizing. Although there are some places mentioned above where it could do better, I'm impressed by what it's able to generate. The quality is a lot better than what I read about in the 6502 community online.
- Assembly output from CC65 could be further optimized by an external program. This would help eliminate some of the redundant instructions identified above, even without access to the C source the assembly came from.
Forth
- Tali Forth 2 is really impressive. The many shortcomings I note above are criticisms of Forth, not specifically of Tali Forth 2. There were no places in the Tali Forth 2 source I found to improve.
- Forth is not for me. I originally considered writing part of the software for the calculator I want to build in Forth, but I will definitely not do that now that I understand what Forth is like.
- Forth's chief advantage seems to be that it can run on low-powered systems and doesn't require cross compiling. It's also neat to have interactability and incremental compilation, even if I didn't use them here. Forth was not very good for implementing a game like this, although I could see how it would be useful in other applications.
- A cross compiled Forth for the 65C02 would be significantly faster. Applying optimizations like CC65 does could lead to a huge increase in performance. On the other hand, it wouldn't solve the problems with unreadability, locals, and the inefficiency of stack based calculation, so that seems like a dead end.
Areas for Improvement
- The optimizing assembler could be greatly streamlined. Instead of expanding macros with NASM, editing the assembly output with the optimizer Python script, then assembling with Macroassembler AS, it would be better to combine all three steps into one Python script.
- Jumps in assembly macros could be more efficient. Conditional jump instructions like BNE and BCC can't jump beyond 128 bytes, so the macros always use a conditional jump paired with a JMP instruction which takes longer. It would be good to find a way to select the right option depending on the jump distance.
- The WHICH macro that works like switch in C could be improved. First, it could use the improved conditional jump macros mentioned above. Second, a binary search algorithm would be faster than testing each option until a match is found.
- Passing arguments in registers would be more efficient. Currently, the macros fill each passed argument into the address of the local variable allocated for it in the called function. Passing one of these arguments in the A register could save at least one LDA and one STA per function call.